Collecting publicly available Bitcoin market data (features) for predictive machine learning models
What bitcoin price is made of?
It all started with me watching the live Bitcoin price chart and seeing that there are changes between buy-side and sell-side in order books on Bitstamp exchange. I was wondering if there is more money on the buy-side than it is on the sell side, does it mean that price is destined to go up? That’s when I decided that I'm a programmer and I can start collecting snapshots of that and analyze those numbers later, so I’ve started collecting buy/sell pressure from the Bitstamp books, I took 10% range from the going price, up and down, added the numbers together and got those 2 numbers of buy and sell pressure. This was the fall of 2017 so the epic Bitcoin rally was on its way.
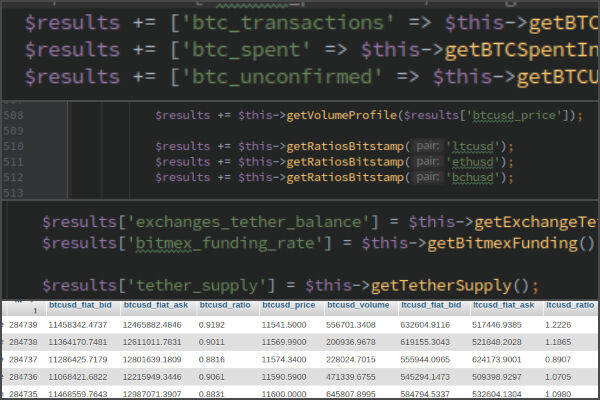
I’ve started analyzing the numbers I’ve collected and I was looking for correlations with future bitcoin price by hand and decided that most likely there are more elements that add up to the making of the price. So I’ve begun collecting other things like volume, alternative coin prices, buy/sell pressure of alternative coins. Then I figured out that I need to get more global numbers, like total crypto market cap changes, total crypto volume, and bitcoin’s blockchain data, like how many coins there were transferred in the last 24 hours, how many unconfirmed transactions we have right now. Then I have spotted that everyone on Reddit is watching Bitfinex’s longs/shorts and added those as well. Later I’ve added things like BitMEX funding rate, BTC dominance ratio, BTC volume ratio so on.
One year prior to all this, I got really interested in Machine Learning specifically neural networks, and I was working on this image recognition project where I needed to filter some content on my company’s website, which was basically an image search engine with millions of photos. At that time doing this with some paid API service would have cost us hundreds of thousands of dollars so we decided to re-train some successful image recognition models with our dataset to solve our business problems. This is where I got my feet wet with so-called AI.
My dataset started growing quite fast, all those features were flowing every 5 minutes and I’ve started generating all kinds of charts to find correlations between the numbers and this became a mess. I knew my dataset is yet too small to try to apply machine learning. I need at least 50k data points (it will take me half a year to collect) and still, I only had knowledge on how to retrain existing vision models like VGG16, no knowledge how to build something from scratch.
Posted 5 years ago by Darius
Add a comment